Understanding Data Skew: The Impact of Data Distribution
Written on
Chapter 1: Introduction to Data Distribution
Understanding how data is stored and retrieved within a database is quite fascinating. Drawing from my experience as a Data Analyst, I will delve into the concept of Data Skew, specifically within relational databases like Teradata.

Chapter 2: Defining Data Skew
When one searches for the term “SKEW,” the definition that emerges is essentially:

In essence, skew indicates something is amiss. Similarly, in a dataset, a non-uniform distribution of data is referred to as Data Skew.
Chapter 3: Sequential vs. Parallel Processing
Before diving deeper into Data Skew, it’s crucial to differentiate between processing methods.

Sequential Processing involves completing one task at a time, executed by a single processor. In this method, when a processor receives a list of tasks, it processes them one after another, causing the other tasks to wait. An example includes a Serial Processing Operating System, which operates on a single processor.
In contrast, Parallel Processing allows multiple tasks to be executed simultaneously across different processors, enhancing speed and efficiency. Systems utilizing multicore processors exemplify this approach.
Chapter 4: Importance of Data Uniformity
Now, why should we be concerned about the uniformity of data stored in a Data Warehouse? Can it impact query performance?
In scenarios where a single processor manages all data, queries are processed sequentially, thereby rendering Data Skew irrelevant. However, in Parallel Processing architectures, where data is distributed across multiple processors, Data Skew becomes a critical factor. The primary advantage of distributed processing is that jobs can be divided into smaller segments, allowing for faster overall completion and improved performance.
Chapter 5: Examining Data Skew Through Case Studies
Let’s analyze two scenarios to illustrate Data Skew:
CASE 1: Non-Uniform Data Distribution (Data Skew)
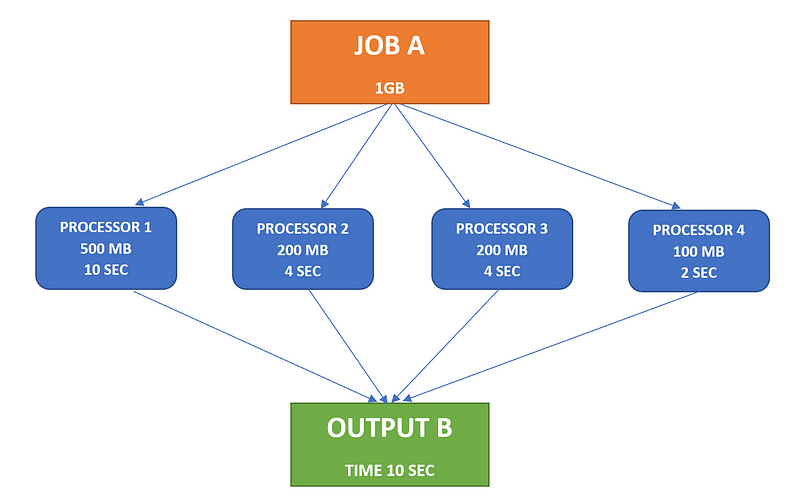
In this case, consider a system with four processors. If data is unevenly distributed, Processor 1 may take 10 seconds to finish its task, while Processor 4 completes its job in just 2 seconds. Despite Processor 4's efficiency, it must wait for Processor 1, resulting in longer execution times—this is termed Data Skew.
CASE 2: Uniform Data Distribution (No Data Skew)
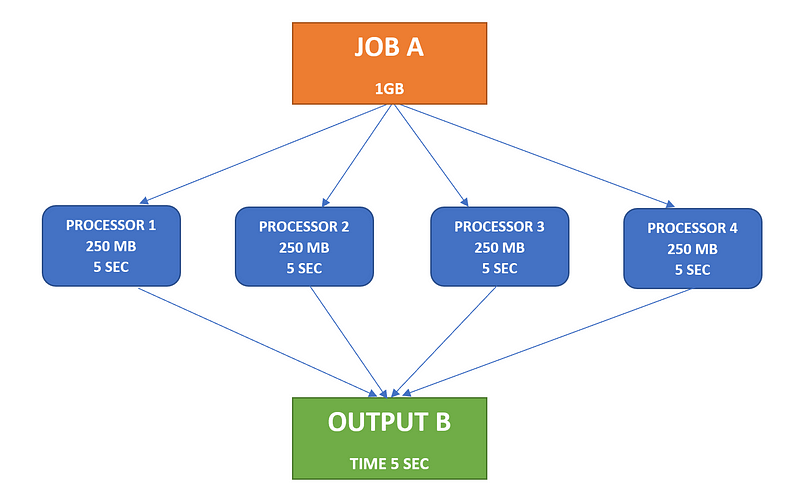
In this scenario, all processors take 5 seconds to complete their tasks. The final output can be compiled promptly once each processor finishes, illustrating that uniform data distribution minimizes execution time and prevents Data Skew.
Chapter 6: Data Skew in Teradata
To further comprehend Data Skew, we can examine the Teradata architecture. The following illustration depicts how data is distributed within Teradata’s parallel processing environment.
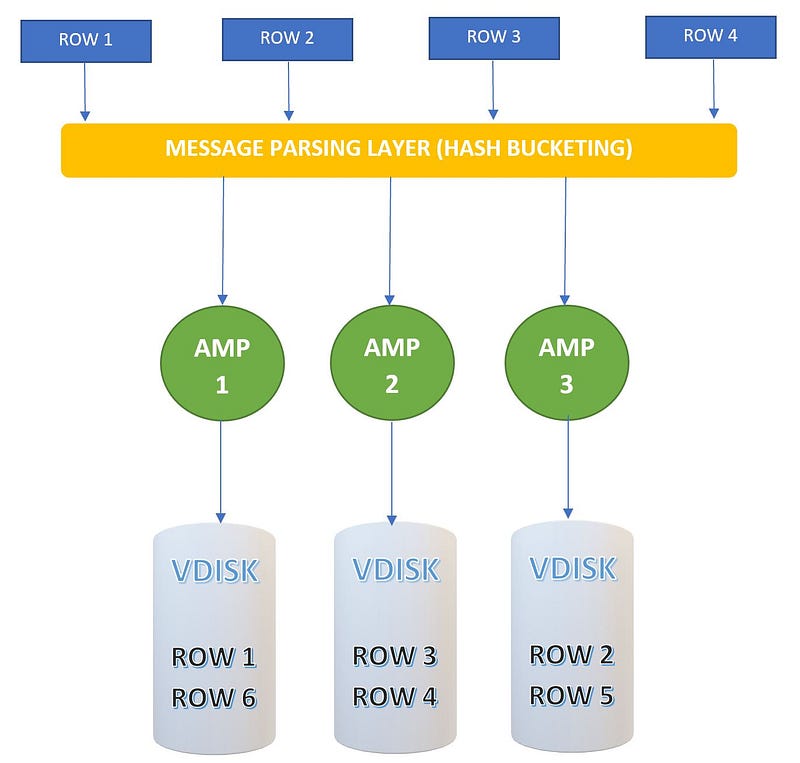
In Teradata, the Access Module Processor (AMP) serves as the virtual processor that manages databases and handles tasks within a multi-tasking, potentially parallel-processing environment. Each AMP operates its own microprocessor and disk subsystem.
Data distribution in Teradata is dictated by the primary index assigned during table creation.
If the CityID is designated as the primary index, it ensures uniform data distribution across AMPs, preventing Data Skew. Conversely, if the CityName—characterized by non-unique values—is chosen as the primary index, it could lead to skewed data distribution, as shown in the histogram below.
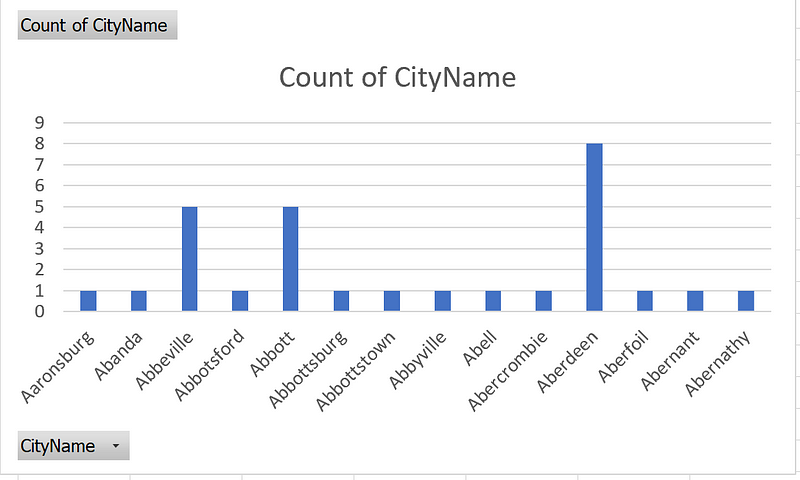
When the number of distinct values is low and the count for each value varies significantly, it negatively impacts data distribution and increases execution time.
Chapter 7: Conclusion
In summary, effective data distribution is pivotal for the performance of parallel processing systems. It’s vital to configure systems to ensure uniform data distribution for optimal performance.
For further reading on related topics, check out the following articles:
Data Warehouse | Dimensional Modelling | Use Case Study: eWallet
“Based on my experience as a Data Engineer and Analyst, I will discuss Data Warehousing and Dimensional modeling…”
Logical Flow of SQL Query | SQL Through the Eye of Database
“For all data analysts, this article changes how to view SQL statements logically.”
Data Analytics | Data Profiling | Use Case Study: Investment Data
“This article explains the major stages involved in many Data Analytics projects, focusing on Data Profiling with investment data…”
References:
- Processing, D., Rehman, J., and Rehman, J., 2021. Difference between serial and parallel processing. [online] IT Release. Available at: [Accessed 8 March 2021].
- www.javatpoint.com. 2021. Teradata Architecture — javatpoint. [online] Available at: [Accessed 8 March 2021].
- Docs.teradata.com. 2021. Teradata Online Documentation | Quick access to technical manuals. [online] Available at: [Accessed 8 March 2021].