Ensemble Methods in Machine Learning: Understanding Bagging and Boosting
Written on
Introduction to Ensemble Learning
Complex challenges often require collaborative solutions. For instance, a weather forecast created by a diverse team of meteorologists will likely yield more accurate predictions than one from a single forecaster. This principle applies equally to machine learning, where ensemble methods harness the power of multiple models to enhance prediction accuracy and improve decision-making processes.
Two prominent strategies in ensemble learning are bagging and boosting. These methods have transformed the training of machine learning models and offer unique advantages that we will explore in depth.
Understanding Bootstrapping
Before diving deeper into bagging and boosting, it's essential to understand bootstrapping, a key concept in ensemble learning. Bootstrapping involves the random sampling of data points from a dataset with replacement. This means that when creating subsets from the original dataset, some samples may appear multiple times.
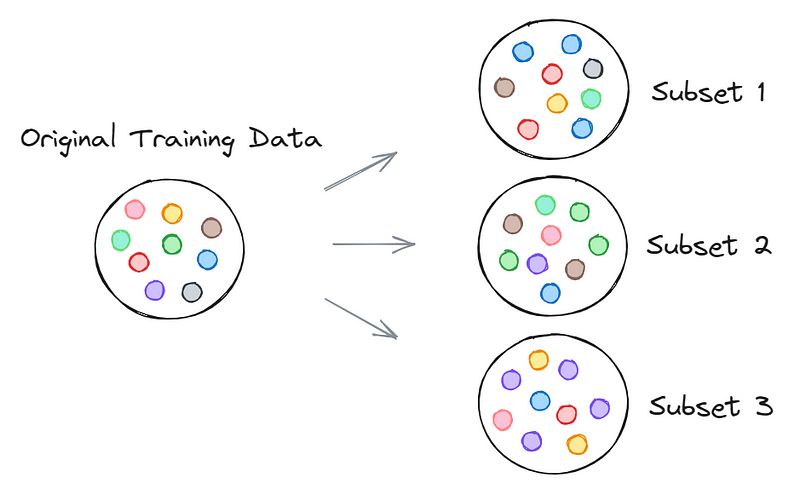
The significance of bootstrapping lies in its ability to provide diverse data perspectives to each model within the ensemble. By generating varied training subsets, bootstrapping helps manage bias and variance, ensuring that the models not only achieve accuracy but maintain it consistently.
The Process of Bagging
Bootstrap aggregating, commonly known as bagging, utilizes bootstrapping to train a weak learner on each subset, often referred to as "bags." A weak learner is characterized as an algorithm that performs slightly better than random guessing.
Bagging operates in parallel, meaning each model is trained independently on its subset. After training, the predictions from each model are combined to produce the final output.
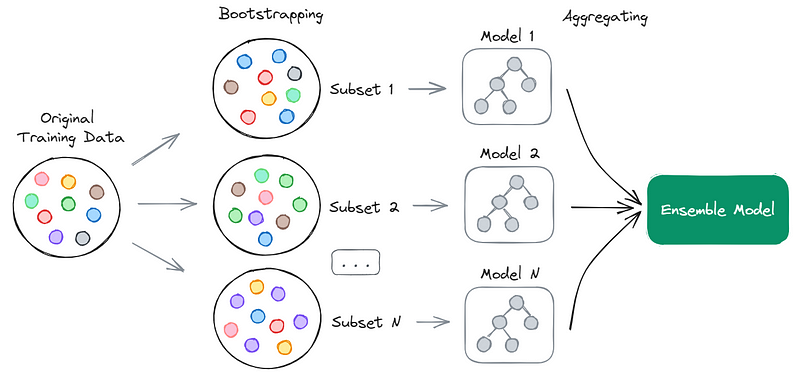
The aggregation method in bagging varies based on the task type:
- For regression tasks, the final prediction is usually the average of the individual weak learners' predictions, which helps reduce variance and improve performance.
- For classification tasks, the final output is determined through majority voting, where the class with the highest votes from individual learners is selected.
Bagging is effective and frequently used to create models that are both stable and accurate, minimizing variance.
Implementations of Bagging
While the core principle of bagging remains similar, different algorithms introduce variations in the process. Notable examples include:
- Random Forests: This widely-used bagging method trains an ensemble of decision trees, each fit on a bootstrapped dataset. Additionally, a random subset of features is selected at each tree split, which helps reduce correlation among trees, enhancing generalization.
- Extra Trees: A modification of random forests, extra trees also employ bootstrapping and random feature subsets, but they randomize the decision thresholds, further increasing diversity among trees.
- Bagging Classifier/Regressor: These are general-purpose bagging wrappers available in libraries like scikit-learn, allowing users to create classifiers or regressors using various algorithms beyond just decision trees.
Exploring Boosting
Unlike bagging, boosting does not typically use bootstrapping and follows a sequential approach. Each new model aims to correct the errors made by its predecessor, thereby reducing bias.
Initially, a weak learner is trained on the entire dataset, with equal weights assigned to all samples. In subsequent iterations, the weights of misclassified samples are increased, while those of correctly classified samples are decreased, thereby emphasizing the importance of the misclassified instances.
This iterative process continues until a predetermined number of iterations are reached or until the desired level of accuracy is achieved. The final predictions are then derived from the combined outputs of all models, weighted by their accuracy.
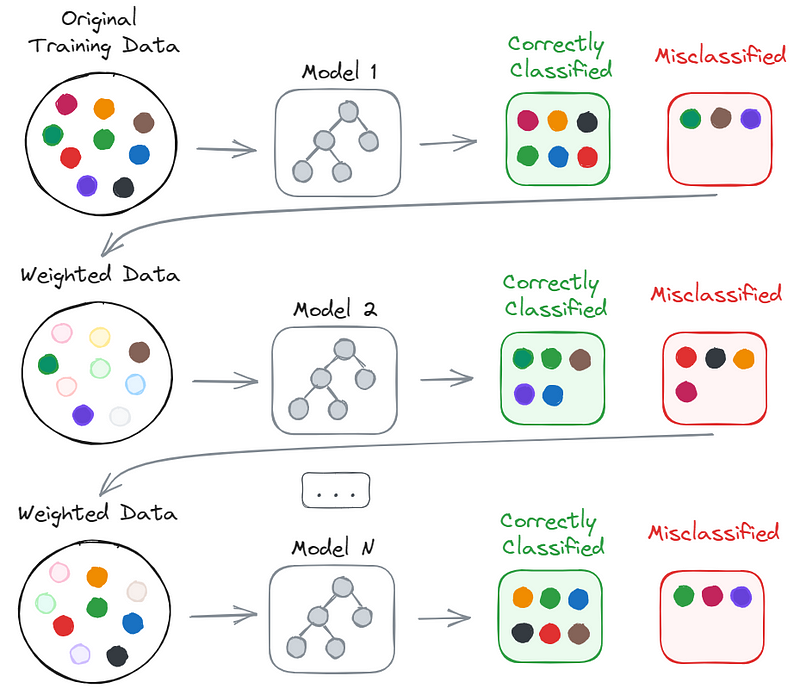
While this explanation focuses on classification, boosting also extends to regression tasks, adjusting sample weights based on the prediction errors.
Implementations of Boosting
The foundational principles of boosting can manifest in various methods, each utilizing distinct techniques for model training and evaluation. Some common methods include:
- AdaBoost: This adaptive boosting technique begins by training a weak learner on the entire dataset and subsequently adjusts weights for misclassified instances in later iterations. Predictions are made by aggregating all weak learners, weighted by their performance scores.
- Gradient Boosting: This method generalizes boosting to various differentiable loss functions, focusing on fitting new learners to the residual errors of prior learners, thus correcting their mistakes.
- XGBoost: Known for its efficiency, XGBoost is an optimized gradient boosting implementation that includes features like regularization to prevent overfitting and effective handling of missing values.
Conclusion
In summary, both bagging and boosting are powerful techniques that enhance predictive modeling by merging multiple weak learners into a single robust learner. Bagging focuses on reducing variance and overfitting through independent learner training on bootstrapped samples, while boosting iteratively refines models to address previous errors and reduce bias.
Although employing these ensemble strategies can add complexity and computational costs, the resulting performance improvements often justify their use. Understanding the trade-offs between these methods is key to effectively applying them to various tasks.
Explore the concepts of ensemble methods including boosting, bagging, and stacking, explained simply for data scientists.
Learn the differences between bagging and boosting in ensemble learning, with clear explanations and examples.