Revolutionizing Image Generation with SDXS: A New Era of Efficiency
Written on
Introduction to SDXS
Recent advancements in diffusion models have positioned them at the leading edge of image generation technologies. However, despite their remarkable capabilities, these models encounter challenges due to complex architectures and high computational needs, resulting in notable delays during the image creation process.

Optimizing SDXS for Speed
The SDXS framework introduces a groundbreaking strategy aimed at reducing latency by miniaturizing models and cutting down on sampling steps. Utilizing knowledge distillation methods, SDXS enhances the U-Net and image decoder architectures, while implementing a novel one-step training approach for diffusion models.
Model Performance
The SDXS-512 and SDXS-1024 variants demonstrate exceptional inference speeds, significantly outpacing earlier iterations. SDXS-512 operates at around 100 frames per second (FPS), which is 30 times quicker than SD v1.5, whereas SDXS-1024 achieves 30 FPS, making it 60 times faster than SDXL on a single GPU.
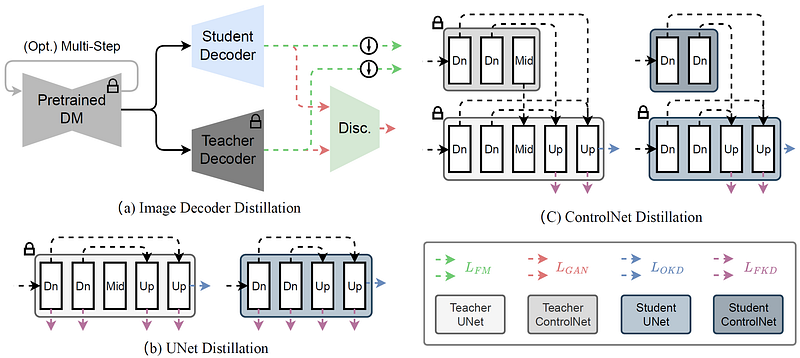
Enhancing Efficiency with a Lightweight Decoder
By training an ultra-lightweight image decoder, SDXS enhances efficiency by emulating the outputs of the original Variational Autoencoder (VAE) decoder. The combination of output distillation and Generative Adversarial Network (GAN) loss, along with a block removal distillation strategy, supports the transfer of knowledge from the original U-Net to a more condensed version.

Advancing Text-to-Image Conversion
To minimize the number of neural function evaluations (NFEs), SDXS proposes methods to reduce sampling steps, including optimizing the sampling trajectory and refining multi-step models into one-step models through feature matching loss. The integration of the Diff-Instruct training strategy further boosts efficiency, enhancing the prompt-following performance compared to earlier versions.
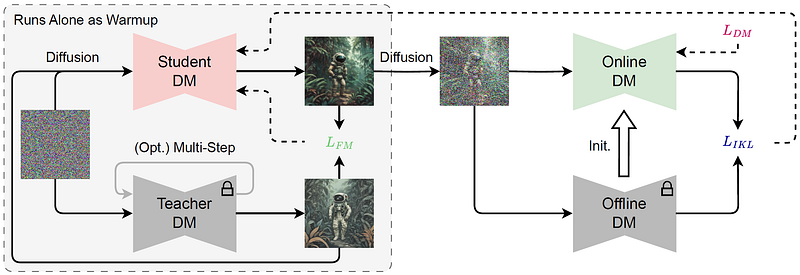
Despite the reductions in model size and sampling steps, SDXS-512 maintains superior prompt-following capabilities compared to SD v1.5. This trend is also evident with the performance of SDXS-1024.

Innovations in Image-to-Image Transformation
Expanding upon our methodology, we integrate ControlNet into the training framework by adding the pretrained ControlNet to the scoring function. This enhancement significantly improves image-to-image transformations, particularly those involving canny edges and depth maps.
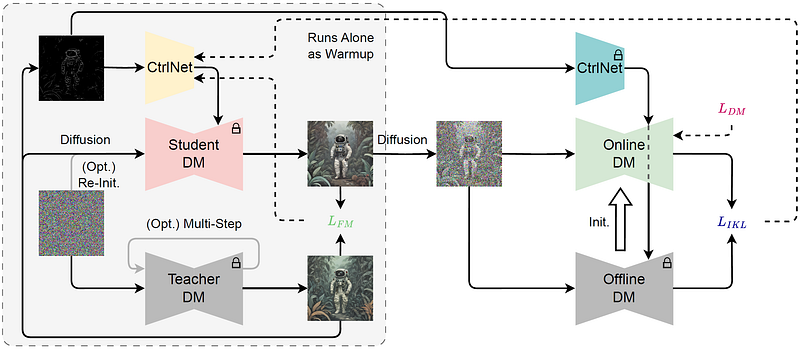
The effectiveness of this approach is evidenced in the ability to facilitate image-to-image conversions, especially for transformations based on canny edges and depth maps.

Try SDXS Online
You can easily experiment with the SDXS Model by following the link below.
SDXS-512-0.9 GPU Demo -1 Steps - a Hugging Face Space by ameerazam08
SDXS 1024 is based on SDXS-512-0.9 and will be released soon.
Conclusion
The advancements showcased in this study not only tackle the latency challenges associated with diffusion models but also pave the way for more efficient image generation and transformation processes. By integrating model optimization techniques with innovative training approaches, significant performance enhancements have been achieved, opening new possibilities for practical applications in various fields that require image generation and manipulation.
Reference Link: Official repository of the paper “SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions”
For All Stable Diffusion Enthusiasts
Thank you for being part of the Stable Diffusion community!
Opportunities in Prompt Engineering and Model Training
Exploring the dynamic intersection of technology, AI art, and model training.